
Abstract: Convolutional neural networks (CNNs) have be come the dominant neural network architecture for solving many state-of-the-art (SOA) visual processing tasks. Even though Graphical Processing Units (GPUs) are most often used in training and deploying CNNs, their power consumption becomes a problem for real time mobile applications. We propose a flexible and efficient CNN accelerator architecture which can support the implementation of SOA CNNs in low-power and low-latency application scenarios. This architecture exploits the sparsity of neuron activations in CNNs to accelerate the computation and reduce memory requirements. The flexible architecture allows full utilization of available computing resources across a wide range of convolutional network kernel sizes; and numbers of input and output feature maps. We implemented the proposed architecture on an FPGA platform and present results showing how our implementation reduces external memory transfers and compute time in five different CNNs ranging from small ones up to the widely known large VGG16 and VGG19 CNNs. We show how in RTL simulations in a 28nm process with a clock frequency of 500 MHz, the NullHop core is able to reach over 450 GOp/s and efficiency of 368%, maintaining over 98% utilization of the MAC units and achieving a power efficiency of over 3 TOp/s/W in a core area of 5.8 mm2
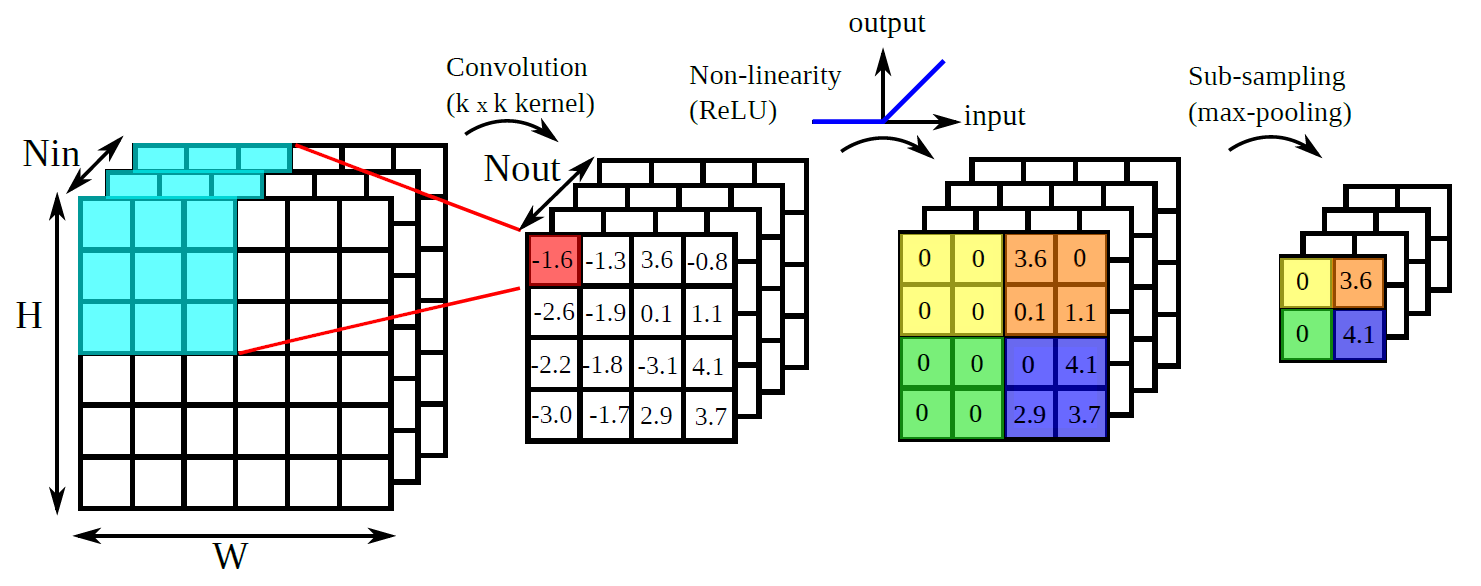 Fig. 1: The three main processing stages in a CNN.
Fig. 1: The three main processing stages in a CNN.
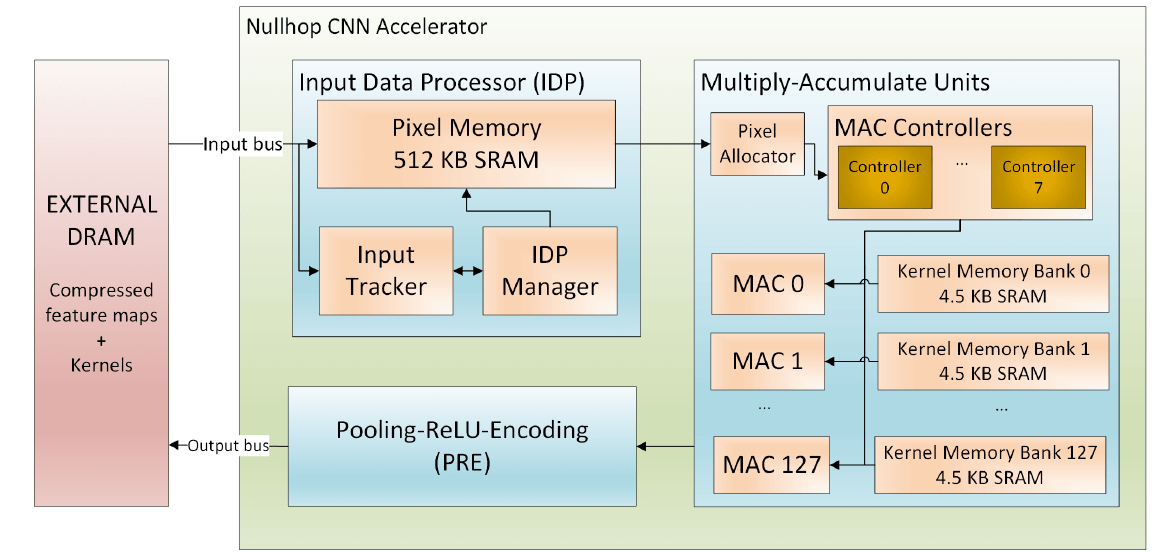 Fig. 4: High-level schematic of the proposed NullHop CNN accelerator.
Fig. 4: High-level schematic of the proposed NullHop CNN accelerator.